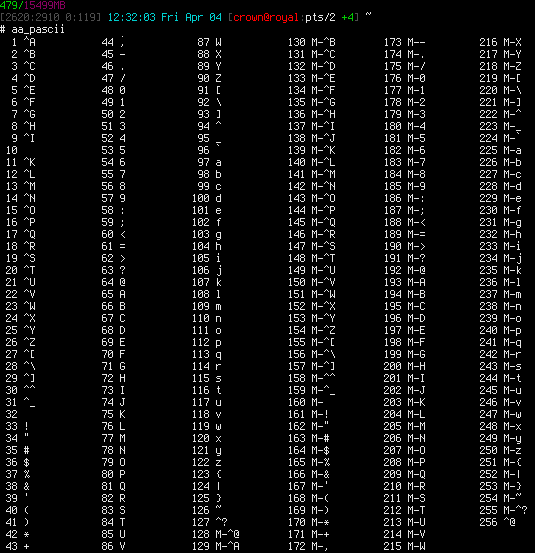
Wanted to stick this here for a reference, mostly for me. I use ASCII alot in bash, preg_matches, preg_replace, etc..
function aa_pascii ()
{
local p=;
for i in {1..256};
do
p=" $i";
echo -e "${p: -3} \\0$(( $i / 64 * 100 + $i % 64 / 8 * 10 + $i % 8 ))";
done | cat -t | column -c$(( ${COLUMNS:-80} / 2 ))
}
The American Standard Code for Information Interchange (ASCII) was developed under the auspices of a committee of the American Standards Association, called the X3 committee, by its X3.2 (later X3L2) subcommittee, and later by that subcommittee's X3.2.4 working group. The ASA became the United States of America Standards Institute or USASI and ultimately the American National Standards Institute.
The X3.2 subcommittee designed ASCII based on earlier teleprinter encoding systems. Like other character encodings, ASCII specifies a correspondence between digital bit patterns and character symbols (i.e. graphemes and control characters). This allows digital devices to communicate with each other and to process, store, and communicate character-oriented information such as written language. Before ASCII was developed, the encodings in use included 26 alphabetic characters, 10 numerical digits, and from 11 to 25 special graphic symbols. To include all these, and control characters compatible with the Comité Consultatif International Téléphonique et Télégraphique (CCITT) International Telegraph Alphabet No. 2 (ITA2) standard, Fieldata, and early EBCDIC, more than 64 codes were required for ASCII.
The committee debated the possibility of a shift key function (like the Baudot code), which would allow more than 64 codes to be represented by six bits. In a shifted code, some character codes determine choices between options for the following character codes. It allows compact encoding, but is less reliable for data transmission; an error in transmitting the shift code typically makes a long part of the transmission unreadable. The standards committee decided against shifting, and so ASCII required at least a seven-bit code.
The committee considered an eight-bit code, since eight bits (octets) would allow two four-bit patterns to efficiently encode two digits with binary coded decimal. However, it would require all data transmission to send eight bits when seven could suffice. The committee voted to use a seven-bit code to minimize costs associated with data transmission. Since perforated tape at the time could record eight bits in one position, it also allowed for a parity bit for error checking if desired. Eight-bit machines (with octets as the native data type) that did not use parity checking typically set the eighth bit to 0.
The code itself was patterned so that most control codes were together, and all graphic codes were together, for ease of identification. The first two columns (32 positions) were reserved for control characters. The "space" character had to come before graphics to make sorting easier, so it became position 20hex; for the same reason, many special signs commonly used as separators were placed before digits. The committee decided it was important to support upper case 64-character alphabets, and chose to pattern ASCII so it could be reduced easily to a usable 64-character set of graphic codes. Lower case letters were therefore not interleaved with upper case. To keep options available for lower case letters and other graphics, the special and numeric codes were arranged before the letters, and the letter "A" was placed in position 41hex to match the draft of the corresponding British standard. The digits 0–9 were arranged so they correspond to values in binary prefixed with 011, making conversion with binary-coded decimal straightforward.
Many of the non-alphanumeric characters were positioned to correspond to their shifted position on typewriters. Thus #, $ and % were placed to correspond to 3, 4, and 5 in the adjacent column. The parentheses could not correspond to 9 and 0, however, because the place corresponding to 0 was taken by the space character. Since many European typewriters placed the parentheses with 8 and 9, those corresponding positions were chosen for the parentheses. The @ symbol was not used in continental Europe and the committee expected it would be replaced by an accented À in the French variation, so the @ was placed in position 40hex next to the letter A.
The control codes felt essential for data transmission were the start of message (SOM), end of address (EOA), end of message (EOM), end of transmission (EOT), "who are you?" (WRU), "are you?" (RU), a reserved device control (DC0), synchronous idle (SYNC), and acknowledge (ACK). These were positioned to maximize the Hamming distance between their bit patterns.
With the other special characters and control codes filled in, ASCII was published as ASA X3.4-1963, leaving 28 code positions without any assigned meaning, reserved for future standardization, and one unassigned control code. There was some debate at the time whether there should be more control characters rather than the lower case alphabet. The indecision did not last long: during May 1963 the CCITT Working Party on the New Telegraph Alphabet proposed to assign lower case characters to columns 6 and 7, and International Organization for Standardization TC 97 SC 2 voted during October to incorporate the change into its draft standard. The X3.2.4 task group voted its approval for the change to ASCII at its May 1963 meeting. Locating the lowercase letters in columns 6 and 7 caused the characters to differ in bit pattern from the upper case by a single bit, which simplified case-insensitive character matching and the construction of keyboards and printers.
The X3 committee made other changes, including other new characters (the brace and vertical line characters), renaming some control characters (SOM became start of header (SOH)) and moving or removing others (RU was removed). ASCII was subsequently updated as USASI X3.4-1967, then USASI X3.4-1968, ANSI X3.4-1977, and finally, ANSI X3.4-1986 (the first two are occasionally retronamed ANSI X3.4-1967, and ANSI X3.4-1968).
The X3 committee also addressed how ASCII should be transmitted (least significant bit first), and how it should be recorded on perforated tape. They proposed a 9-track standard for magnetic tape, and attempted to deal with some forms of punched card formats.
ASCII itself was first used commercially during 1963 as a seven-bit teleprinter code for American Telephone & Telegraph's TWX (TeletypeWriter eXchange) network. TWX originally used the earlier five-bit Baudot code, which was also used by the competing Telex teleprinter system. Bob Bemer introduced features such as the escape sequence. His British colleague Hugh McGregor Ross helped to popularize this work—according to Bemer, "so much so that the code that was to become ASCII was first called the Bemer-Ross Code in Europe". Because of his extensive work on ASCII, Bemer has been called "the father of ASCII."
On March 11, 1968, U.S. President Lyndon B. Johnson mandated that all computers purchased by the United States federal government support ASCII, stating:
I have also approved recommendations of the Secretary of Commerce regarding standards for recording the Standard Code for Information Interchange on magnetic tapes and paper tapes when they are used in computer operations. All computers and related equipment configurations brought into the Federal Government inventory on and after July 1, 1969, must have the capability to use the Standard Code for Information Interchange and the formats prescribed by the magnetic tape and paper tape standards when these media are used.
Other international standards bodies have ratified character encodings such as ISO/IEC 646 that are identical or nearly identical to ASCII, with extensions for characters outside the English alphabet and symbols used outside the United States, such as the symbol for the United Kingdom's pound sterling (£). Almost every country needed an adapted version of ASCII, since ASCII suited the needs of only the USA and a few other countries. For example, Canada had its own version that supported French characters. Other adapted encodings include ISCII (India), VISCII (Vietnam), and YUSCII (Yugoslavia). Although these encodings are sometimes referred to as ASCII, true ASCII is defined strictly only by ANSI standard.
ASCII was incorporated into the Unicode character set as the first 128 symbols, so the ASCII characters have the same numeric codes in both sets. This allows UTF-8 to be backward compatible with ASCII, a significant advantage.
ASCII reserves the first 32 codes (numbers 0–31 decimal) for control characters: codes originally intended not to represent printable information, but rather to control devices (such as printers) that make use of ASCII, or to provide meta-information about data streams such as those stored on magnetic tape. For example, character 10 represents the "line feed" function (which causes a printer to advance its paper), and character 8 represents "backspace". RFC 2822 refers to control characters that do not include carriage return, line feed or white space as non-whitespace control characters. Except for the control characters that prescribe elementary line-oriented formatting, ASCII does not define any mechanism for describing the structure or appearance of text within a document. Other schemes, such as markup languages, address page and document layout and formatting.
The original ASCII standard used only short descriptive phrases for each control character. The ambiguity this caused was sometimes intentional (where a character would be used slightly differently on a terminal link than on a data stream) and sometimes accidental (such as what "delete" means).
Probably the most influential single device on the interpretation of these characters was the Teletype Model 33 ASR, which was a printing terminal with an available paper tape reader/punch option. Paper tape was a very popular medium for long-term program storage until the 1980s, less costly and in some ways less fragile than magnetic tape. In particular, the Teletype Model 33 machine assignments for codes 17 (Control-Q, DC1, also known as XON), 19 (Control-S, DC3, also known as XOFF), and 127 (Delete) became de facto standards. Because the keytop for the O key also showed a left-arrow symbol (from ASCII-1963, which had this character instead of underscore), a noncompliant use of code 15 (Control-O, Shift In) interpreted as "delete previous character" was also adopted by many early timesharing systems but eventually became neglected.
The use of Control-S (XOFF, an abbreviation for transmit off) as a "handshaking" signal warning a sender to stop transmission because of impending overflow, and Control-Q (XON, "transmit on") to resume sending, persists to this day in many systems as a manual output control technique. On some systems Control-S retains its meaning but Control-Q is replaced by a second Control-S to resume output.
Code 127 is officially named "delete" but the Teletype label was "rubout". Since the original standard did not give detailed interpretation for most control codes, interpretations of this code varied. The original Teletype meaning, and the intent of the standard, was to make it an ignored character, the same as NUL (all zeroes). This was useful specifically for paper tape, because punching the all-ones bit pattern on top of an existing mark would obliterate it. Tapes designed to be "hand edited" could even be produced with spaces of extra NULs (blank tape) so that a block of characters could be "rubbed out" and then replacements put into the empty space.
As video terminals began to replace printing ones, the value of the "rubout" character was lost. DEC systems, for example, interpreted "Delete" to mean "remove the character before the cursor" and this interpretation also became common in Unix systems. Most other systems used "Backspace" for that meaning and used "Delete" to mean "remove the character at the cursor". That latter interpretation is the most common now.
Many more of the control codes have been given meanings quite different from their original ones. The "escape" character (ESC, code 27), for example, was intended originally to allow sending other control characters as literals instead of invoking their meaning. This is the same meaning of "escape" encountered in URL encodings, C language strings, and other systems where certain characters have a reserved meaning. Over time this meaning has been co-opted and has eventually been changed. In modern use, an ESC sent to the terminal usually indicates the start of a command sequence, usually in the form of a so-called "ANSI escape code" (or, more properly, a "Control Sequence Introducer") beginning with ESC followed by a "[" (left-bracket) character. An ESC sent from the terminal is most often used as an out-of-band character used to terminate an operation, as in the TECO and vi text editors. In graphical user interface (GUI) and windowing systems, ESC generally causes an application to abort its current operation or to exit (terminate) altogether.
The inherent ambiguity of many control characters, combined with their historical usage, created problems when transferring "plain text" files between systems. The best example of this is the newline problem on various operating systems. Teletype machines required that a line of text be terminated with both "Carriage Return" (which moves the printhead to the beginning of the line) and "Line Feed" (which advances the paper one line without moving the printhead). The name "Carriage Return" comes from the fact that on a manual typewriter the carriage holding the paper moved while the position where the keys struck the ribbon remained stationary. The entire carriage had to be pushed (returned) to the right in order to position the left margin of the paper for the next line.
DEC operating systems (OS/8, RT-11, RSX-11, RSTS, TOPS-10, etc.) used both characters to mark the end of a line so that the console device (originally Teletype machines) would work. By the time so-called "glass TTYs" (later called CRTs or terminals) came along, the convention was so well established that backward compatibility necessitated continuing the convention. When Gary Kildall cloned RT-11 to create CP/M he followed established DEC convention. Until the introduction of PC-DOS in 1981, IBM had no hand in this because their 1970s operating systems used EBCDIC instead of ASCII and they were oriented toward punch-card input and line printer output on which the concept of "carriage return" was meaningless. IBM's PC-DOS (also marketed as MS-DOS by Microsoft) inherited the convention by virtue of being a clone of CP/M, and Windows inherited it from MS-DOS.
Unfortunately, requiring two characters to mark the end of a line introduces unnecessary complexity and questions as to how to interpret each character when encountered alone. To simplify matters, plain text files on Multics, Unix and Unix-like systems, and Amiga systems use line feed (LF) alone as a line terminator. The original Macintosh OS, on the other hand, used carriage return (CR) alone as a line terminator; however, since Apple replaced it with the Unix-based OS X operating system, they now use line feed (LF) as well.
Transmission of text over the Internet, for protocols as E-mail and the World Wide Web, uses both characters.
Operating systems such as some older DEC operating systems, along with CP/M, tracked file length only in units of disk blocks and used Control-Z (SUB) to mark the end of the actual text in the file. For this reason, EOF, or end-of-file, was used colloquially and conventionally as a three-letter acronym (TLA) for Control-Z instead of SUBstitute. For a variety of reasons, the end-of-text code, ETX aka Control-C, was inappropriate and using Z as the control code to end a file is analogous to it ending the alphabet, a very convenient mnemonic aid.
In C library and Unix conventions, the null character is used to terminate text strings; such null-terminated strings can be known in abbreviation as ASCIZ or ASCIIZ, where here Z stands for "zero".
Codes 0 through 31 and 127 (decimal) are unprintable control characters. Code 32 (decimal) is a nonprinting spacing characer. Codes 33 through 126 (decimal) are printable graphic characters.
Binary Oct Dec Hex Glyph
010 0000 040 32 20
010 0001 041 33 21 !
010 0010 042 34 22 "
010 0011 043 35 23 #
010 0100 044 36 24 $
010 0101 045 37 25 %
010 0110 046 38 26 &
010 0111 047 39 27 '
010 1000 050 40 28 (
010 1001 051 41 29 )
010 1010 052 42 2A *
010 1011 053 43 2B +
010 1100 054 44 2C ,
010 1101 055 45 2D -
010 1110 056 46 2E .
010 1111 057 47 2F /
011 0000 060 48 30 0
011 0001 061 49 31 1
011 0010 062 50 32 2
011 0011 063 51 33 3
011 0100 064 52 34 4
011 0101 065 53 35 5
011 0110 066 54 36 6
011 0111 067 55 37 7
011 1000 070 56 38 8
011 1001 071 57 39 9
011 1010 072 58 3A :
011 1011 073 59 3B ;
011 1100 074 60 3C <
011 1101 075 61 3D =
011 1110 076 62 3E >
011 1111 077 63 3F ?
100 0000 100 64 40 @
100 0001 101 65 41 A
100 0010 102 66 42 B
100 0011 103 67 43 C
100 0100 104 68 44 D
100 0101 105 69 45 E
100 0110 106 70 46 F
100 0111 107 71 47 G
100 1000 110 72 48 H
100 1001 111 73 49 I
100 1010 112 74 4A J
100 1011 113 75 4B K
100 1100 114 76 4C L
100 1101 115 77 4D M
100 1110 116 78 4E N
100 1111 117 79 4F O
101 0000 120 80 50 P
101 0001 121 81 51 Q
101 0010 122 82 52 R
101 0011 123 83 53 S
101 0100 124 84 54 T
101 0101 125 85 55 U
101 0110 126 86 56 V
101 0111 127 87 57 W
101 1000 130 88 58 X
101 1001 131 89 59 Y
101 1010 132 90 5A Z
101 1011 133 91 5B [
101 1100 134 92 5C
101 1101 135 93 5D ]
101 1110 136 94 5E ^
101 1111 137 95 5F _
110 0000 140 96 60 `
110 0001 141 97 61 a
110 0010 142 98 62 b
110 0011 143 99 63 c
110 0100 144 100 64 d
110 0101 145 101 65 e
110 0110 146 102 66 f
110 0111 147 103 67 g
110 1000 150 104 68 h
110 1001 151 105 69 i
110 1010 152 106 6A j
110 1011 153 107 6B k
110 1100 154 108 6C l
110 1101 155 109 6D m
110 1110 156 110 6E n
110 1111 157 111 6F o
111 0000 160 112 70 p
111 0001 161 113 71 q
111 0010 162 114 72 r
111 0011 163 115 73 s
111 0100 164 116 74 t
111 0101 165 117 75 u
111 0110 166 118 76 v
111 0111 167 119 77 w
111 1000 170 120 78 x
111 1001 171 121 79 y
111 1010 172 122 7A z
111 1011 173 123 7B {
111 1100 174 124 7C |
111 1101 175 125 7D }
111 1110 176 126 7E ~
000 or = 001 or = 002 or = 003 or = 004 or = 005 or = 006 or = 007 or = 008 or = 009 or = 010 or = 011 or = 012 or = 013 or = 014 or = 015 or = 016 or = 017 or = 018 or = 019 or = 020 or = 021 or = 022 or = 023 or = 024 or = 025 or = 026 or = 027 or = 028 or = 029 or = 030 or = 031 or = 032 or =
033 or ! = ! 034 or " = " 035 or # = # 036 or $ = $ 037 or % = % 038 or & = & 039 or ' = ' 040 or ( = ( 041 or ) = ) 042 or * = * 043 or + = + 044 or , = , 045 or - = - 046 or . = . 047 or / = /
048 or 0 = 0 049 or 1 = 1 050 or 2 = 2 051 or 3 = 3 052 or 4 = 4 053 or 5 = 5 054 or 6 = 6 055 or 7 = 7 056 or 8 = 8 057 or 9 = 9
058 or : = : 059 or ; = ; 060 or < = < 061 or = = = 062 or > = > 063 or ? = ? 064 or @ = @
065 or A = A 066 or B = B 067 or C = C 068 or D = D 069 or E = E 070 or F = F 071 or G = G 072 or H = H 073 or I = I 074 or J = J 075 or K = K 076 or L = L 077 or M = M 078 or N = N 079 or O = O 080 or P = P 081 or Q = Q 082 or R = R 083 or S = S 084 or T = T 085 or U = U 086 or V = V 087 or W = W 088 or X = X 089 or Y = Y 090 or Z = Z
091 or [ = [ 092 or \ = 093 or ] = ] 094 or ^ = ^ 095 or _ = _ 096 or ` = `
097 or a = a 098 or b = b 099 or c = c 100 or d = d 101 or e = e 102 or f = f 103 or g = g 104 or h = h 105 or i = i 106 or j = j 107 or k = k 108 or l = l 109 or m = m 110 or n = n 111 or o = o 112 or p = p 113 or q = q 114 or r = r 115 or s = s 116 or t = t 117 or u = u 118 or v = v 119 or w = w 120 or x = x 121 or y = y 122 or z = z
123 or { = {
124 or | = |
125 or } = }
126 or ~ = ~
127 or =
128 or = €
129 or =
130 or = ‚
131 or = ƒ
132 or = „
133 or
= …
134 or = †
135 or = ‡
136 or = ˆ
137 or = ‰
138 or = Š
139 or = ‹
140 or = Œ
141 or =
142 or = Ž
143 or =
144 or =
145 or = ‘
146 or = ’
147 or = “
148 or = ”
149 or = •
150 or = –
151 or = —
152 or = ˜
153 or = ™
154 or = š
155 or = ›
156 or = œ
157 or =
158 or = ž
159 or = Ÿ
160 or =
161 or ¡ = ¡
162 or ¢ = ¢
163 or £ = £
164 or ¤ = ¤
165 or ¥ = ¥
166 or ¦ = ¦
167 or § = §
168 or ¨ = ¨
169 or © = ©
170 or ª = ª
171 or « = «
172 or ¬ = ¬
173 or =
174 or ® = ®
175 or ¯ = ¯
176 or ° = °
177 or ± = ±
178 or ² = ²
179 or ³ = ³
180 or ´ = ´
181 or µ = µ
182 or ¶ = ¶
183 or · = ·
184 or ¸ = ¸
185 or ¹ = ¹
186 or º = º
187 or » = »
188 or ¼ = ¼
189 or ½ = ½
190 or ¾ = ¾
191 or ¿ = ¿
192 or À = À
193 or Á = Á
194 or  = Â
195 or à = Ã
196 or Ä = Ä
197 or Å = Å
198 or Æ = Æ
199 or Ç = Ç
200 or È = È
201 or É = É
202 or Ê = Ê
203 or Ë = Ë
204 or Ì = Ì
205 or Í = Í
206 or Î = Î
207 or Ï = Ï
208 or Ð = Ð
209 or Ñ = Ñ
210 or Ò = Ò
211 or Ó = Ó
212 or Ô = Ô
213 or Õ = Õ
214 or Ö = Ö
215 or × = ×
216 or Ø = Ø
217 or Ù = Ù
218 or Ú = Ú
219 or Û = Û
220 or Ü = Ü
221 or Ý = Ý
222 or Þ = Þ
223 or ß = ß
224 or à = à
225 or á = á
226 or â = â
227 or ã = ã
228 or ä = ä
229 or å = å
230 or æ = æ
231 or ç = ç
232 or è = è
233 or é = é
234 or ê = ê
235 or ë = ë
236 or ì = ì
237 or í = í
238 or î = î
239 or ï = ï
240 or ð = ð
241 or ñ = ñ
242 or ò = ò
243 or ó = ó
244 or ô = ô
245 or õ = õ
246 or ö = ö
247 or ÷ = ÷
248 or ø = ø
249 or ù = ù
250 or ú = ú
251 or û = û
252 or ü = ü
253 or ý = ý
254 or þ = þ
255 or ÿ = ÿ
This page contains content from article and is released under the CC-BY-SA.